360doc网络爬虫 -- 自动抽取互联网信息,并结构化入库
BAT日报讯:随着网络的迅速发展,万维网成为最大的信息载体,由于关键信息都是以半结构化或自由文本形式存在于HTML网页中,因此无法直接利用,如何有效地提取并利用这些信息成为一个巨大的挑战。
360doc网络爬虫,可根据用户自定义的任务配置,批量、精准地自动抽取因特网目标网页中的半结构化与非结构化数据,转化为结构化的记录,保存在本地数据库中,用于内部使用或外网发布,实现因特网上信息的快速获取。
360doc网络爬虫特点
◆多线程支持:采集支持多线程,实现快速信息采集;
◆分布式支持:可组成采集服务器集群进行大规模数据采集;
◆支持采集报警:通过管理监控模块,能够对发生变化的信息源网站进行自动提示和报警;
◆支持中英文语种;
◆精确采集定位策略:可以指定采集的网站的具体栏目;
◆支持增量更新:每次只采集上次更新后新生成或更改的网页,保证信息更新的效率;
◆灵活设定更新时间及间隔:对采集网站进行安排和计划,采用定时和循环两种运行机制,保证系统的性能稳定和采集效能最大化;
◆支持Proxy代理服务器;
◆格式化精确抽取:精确抽取用户设定的有用内容,如:文章的标题、作者、日期、正文、来源等,去除页面上的无用信息,如:页面上的广告、版权、栏目等,抽取结果无需二次加工;支持文章中的图片、图表的抽取;自动进行文章列表翻页和文章页翻页,自动进行多页拼接;
◆支持采集排重:支持多种方式排重策略,可根据URL、站点、作者等属性值实现信息排重,也可根据相关性原则进行数据排重,对内容相似度达到某一阀值的网页进行排重操作。
图1 设定爬取站点
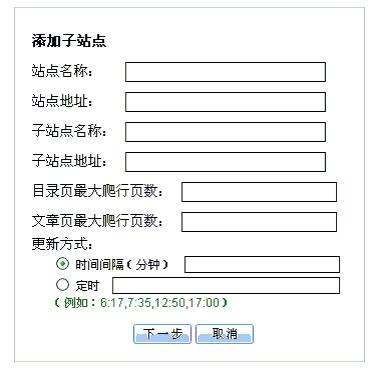
图2 爬虫抽取结果文章列表
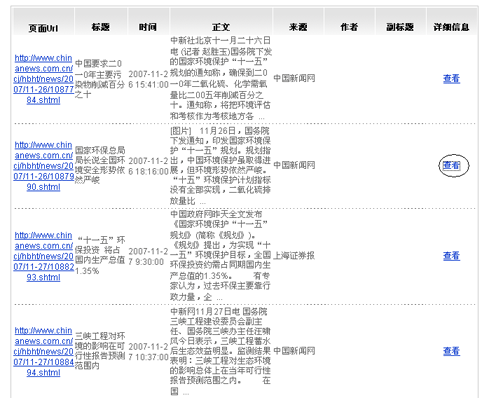
图3 查看文章抽取结果