屠可伟课题组在自然语言处理领域取得多项成果
近日,上海科技大学信息学院视觉与数据智能中心屠可伟课题组在 Empirical Methods in Natural Language Processing (EMNLP 2020) 发表3篇主会论文以及4篇扩展论文集论文,展示了他们在自然语言处理领域的最新研究成果。EMNLP是自然语言处理领域三大顶级会议(ACL、EMNLP 和 NAACL)之一,在国际上享有很高的声誉,根据Google Scholar Metrics,在人工智能领域所有期刊与会议中排名前十。EMNLP 2020的论文录用率为22%。
在主会论文Cold-start and Interpretability: Turning Regular Expressions into Trainable Recurrent Neural Networks中,课题组提出了一种将正则表达式转化为循环神经网络的方法。正则表达式是自然语言处理领域最常用的符号规则形式之一,有着较高的可解释性以及精确率,却无法像神经网络一样由数据训练从而提升效果。相较而言,神经网络在有足够多标注数据的情况下往往效果惊人,但当标注数据匮乏时性能就会大打折扣。此外,神经网络也缺少可解释性以及难以融入外部知识。屠可伟课题组将正则表达式对应的有限状态自动机转化为一种可学习的循环神经网络,以结合符号规则与神经网络的优点。在文本分类任务上的实验表明,正则表达式转化而成的循环神经网络在零样本时有着和正则表达式相当的准确率,远高于随机初始化的神经网络;在小样本的场景下也有着明显优势;在样本足够多的场景下则有着和神经网络相当的效果。屠可伟课题组2019级硕士生蒋承越是本文第一作者,乐言科技为合作单位,屠可伟教授为通讯作者。项目获得乐言科技和国家自然科学基金委支持。
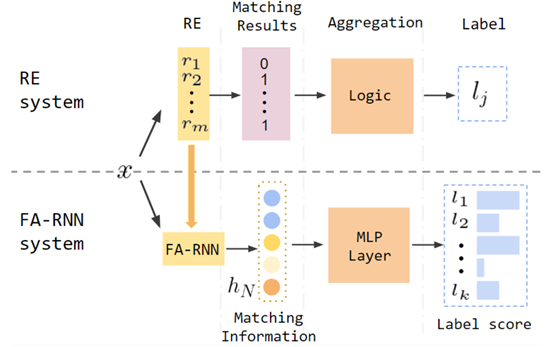
图|本文提出的框架示意图
在主会论文 Adversarial Attack and Defense of Structured Prediction Models 中,课题组研究了自然语言处理结构预测问题上的对抗样本生成。对抗样本是指目标预测器易于出错的样本,找到对抗样本有利于提升模型的鲁棒性并提升模型的效果。目前绝大多数对抗样本方向的工作都是针对图像领域和自然语言处理领域中的分类问题,针对结构预测的对抗样本研究仍是空白。屠可伟课题组针对于这一问题,提出了一种基于强化学习的对抗样本生成架构,超越了传统方法的性能,并具有黑箱、在线、可变句子长度等优势。屠可伟课题组2020届博士毕业生(现新加坡国立大学博士后)韩文娟和2018级博士生张力文为本文的共同第一作者,屠可伟教授为通讯作者。项目获得国家自然科学基金委支持。
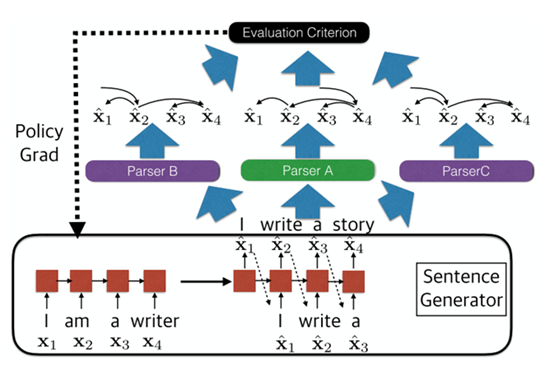
图|本文提出的框架示意图
在主会论文AIN: Fast and Accurate Sequence Labeling with Approximate Inference Network中,课题组研究了序列标注问题的快速并行方法。序列标注是自然语言处理中一项非常重要的基础任务,在大量的搜索推荐广告、电商等业务场景都有广泛的应用。而这些场景往往都需要快速地处理用户需求,从而提升用户体验。现有的序列标注模块往往采用条件随机场模型处理,但针对条件随机场模型推理的常用算法如Viterbi算法,无法实现序列内部每个词之间的并行计算,导致速度慢效率低。屠可伟课题组提出了使用平均场变分推理算法来对条件随机场进行近似推理,通过反复迭代的方式更新其预测的概率分布达到收敛。论文将平均场变分推理算法看作一个端到端的循环神经网络结构,使得词之间的并行计算成为可能。实验表明,该方法大幅度提升了序列标注模型的训练和测试速度,同时准确度也保持在和传统算法几乎相同的水平。屠可伟课题组2020级博士生王新宇是本文第一作者,阿里巴巴达摩院为合作单位,屠可伟教授为通讯作者。项目获得阿里巴巴达摩院和国家自然科学基金委支持。(文/上海科技大学)