百度大脑“小度”3:2战胜最强大脑人类选手王峰
1月6日江苏卫视《最强大脑》,上演了一场精彩的人机对决,这次的战场不再是围棋,而是人脸识别。

人类的出战代表为王峰(微博),其为90后世界记忆大师,《最强大脑》名人堂轮值主席。
2015年以队长身份参加《最强大脑第二季》,在《最强大脑》中德国际对抗赛中,王峰率领中国代表队4:0完胜德国队,本人以一敌二,并打破快速记忆扑克牌世界纪录。
机器的一方则是百度机器人“小度”,百度大脑在人工智能领域的很多研究成果都植入到其身上。
“百度大脑”已建成超大规模的神经网络,拥有万亿级的参数、千亿样本、千亿特征训练,能模拟人脑的工作机制。百度大脑如今智商已经有了超前的发展,在一些能力上甚至超越了人类。
在人脸识别技术的国际测评中,百度最高能达到99.77%的准确率,2015年曾获得过两次世界第一。而人机大战的第一场就是PK人脸识别。
“小度”将与名人堂选手约战三场,主要在人脸识别、语音识别上面PK,前三期人机大战,采用三局两胜制,如果百度大脑全胜,将参加角逐最后的脑王争霸。
第一轮:跨年龄识别
嘉宾(章子怡)从20张蜜蜂少女队成员童年照中挑出3张高难度照片,选手通过动态录像表演将所选童年照和在场的成年少女向匹配。选择正确者得1分。
蜜蜂少女队人员众多且每个人在赛场上化妆表演, 不排除有微整形、戴美瞳等因素干扰。
此外,挑选的童年照都在0-4岁范围内,与现在成年少女队的年龄跨度比较大。
同时,比赛现场有实时照片传输、现场摄影机捕捉人脸图像晃动、灯光干扰等因素都会影响人工智能的识别准确率。
最为困难的是,蜜蜂少女队人员中有一对双胞胎,恰巧被现场嘉宾抽中。

最终,事先并不知情的王峰未能从双胞胎中区分出差别,导致判断错误,第一轮得0分。


而百度机器人则给出了两个结果,区别是相似度仅相差0.01%,相似度较高那个最终被证明是正确答案,从而拿到第一轮的1分。
第一轮过后,人机大战的比分是1:0,人类暂时落后。
第二轮:千脸跨年龄识别
人机共同观察一位30岁以上的观众,随后将他从30张小学集体照中找出。这一轮在上一轮的基础上增加了难度,因此分值提高,选择正确者得2分。

这一回合样本容量大,30张集体照大约需要在1000-2000个人脸中找到对应的人,年龄跨度也覆盖在80、90后等年龄层中。

最终,机器和王峰先后在合照中正确识别出了嘉宾选择出的观众,均得2分。加上第一轮的得分,机器最终得3分,王峰得2分。
经过两轮角逐,百度机器人以微弱优势胜出,王峰为双胞胎那万分之一的差别付出了代价。
人脸识别的技术难点
人类大脑从上百万年前开始就拥有了人脸识别的能力,而机器没有直觉,也并没有久远的进化历史,只能靠分析数据来学习。
计算机只认识0和1,所以它必须通过无数次的学习来找到人类直觉的规律并将它转变成0和1存储在脑子里,从而模拟人类通过直觉思考的过程。
人脸识别技术研究的困难,不同于普通的图像识别。就人的脸部特征而言,每个人的脸部结构都是相似的,这对于利用人脸区分人类个体不利,还有一些特殊情况,比如双胞胎甚至多胞胎。
其次就是表情、光照条件、整容等外因影响。不同的表情、角度观察,光照条件的影响,人脸遮盖物,如口罩、墨镜、头发、胡须,甚至是整容、P图等行为,都增加了人脸识别的难度。
而对双胞胎的识别,技术上就更困难了。
人脸识别是在脸部骨骼上取尽可能多的点,通过计算机把这些点分别与自己已经存储的脸比较,有差别就判断出来了。因为双胞胎骨骼太相似,导致差别特别细微,所以取的面部骨骼点不够多的话是识别不出来的。
人脸识别主要步骤
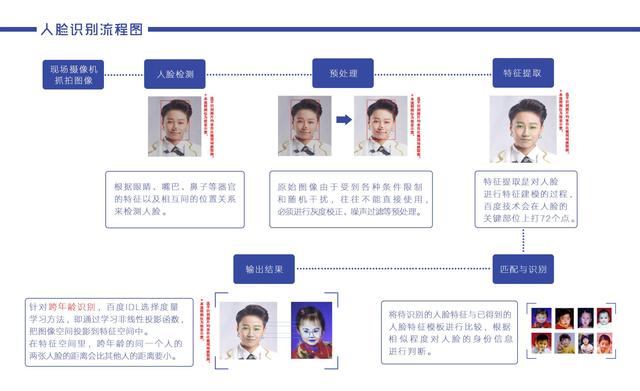
(以比赛为例,现场小度识别蜜蜂少女成员的原理流程图)
具体分解如下:
Step 1 人脸检测:
根据眼睛、眉毛、嘴巴、鼻子等器官的特征以及相互之间的几何位置关系来检测人脸,即在在一副图像或一序列图像(比如视频)中判断是否有人脸,若有则返回人脸的大小、位置等信息。

Step 2 人脸图像预处理:
系统获取的原始图像由于受到各种条件的限制和随机干扰,往往不能直接使用,必须在图像处理的早期阶段对它进行灰度校正、噪声过滤等图像预处理。
人脸图像的预处理主要包括人脸对准,人脸图像的增强,以及归一化等工作。
人脸对准是为了得到人脸位置端正的人脸图像;
图像增强是为了改善人脸图像的质量,不仅在视觉上更加清晰图像,而且使图像更利于计算机的处理与识别。
归一化工作的目标是取得尺寸一致,灰度取值范围相同的标准化人脸图像。
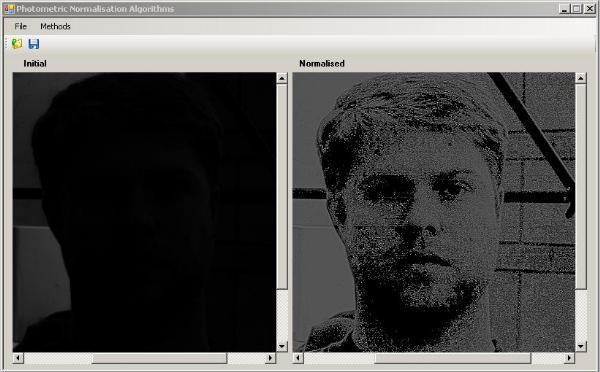
【人脸图像的预处理】
Step 3 人脸图像特征提取:
人脸特征提取就是针对人脸的某些特征进行的。人脸特征提取,也称人脸表征,它是对人脸进行特征建模的过程。

Step 4 人脸图像匹配与识别:
人脸识别就是将待识别的人脸特征与已得到的人脸特征模板进行比较,根据相似程度对人脸的身份信息进行判断。这一过程又分为两类:
一类是人脸确认,是一对一进行图像比较的过程,将某人面像与指定人员面像进行一对一的比对,根据其相似程度(一般以是否达到或超过某一量化的可信度指标/阀值为依据)来判断二者是否是同一人。
另一类是人脸辨认,是一对多进行图像匹配对比的过程。将某人面像与数据库中的多人的人脸进行比对(有时也称“一对多”比对),并根据比对结果来鉴定此人身份,或找到其中最相似的人脸,并按相似程度的大小输出检索结果。
百度大脑提升跨年龄人脸识别的方法
影响人脸识别的因素有很多,其中影响人脸检测的因素有:光照、人脸姿态、遮挡程度;
影响特征提取的因素有:光照、表情、遮挡、年龄、模糊是影响人脸识别精度的关键因素。而在跨年龄人脸检测中影响因素更多。
一般而言,在跨年龄阶段人脸识别中,类内变化通常会大于类间变化,这造成了人脸识别的巨大困难。同时,跨年龄的训练数据难以收集。没有足够多的数据,基于深度学习的神经网络很难学习到跨年龄的类内和类间变化。
基于第一点,百度IDL的人脸团队选择用度量学习的方法。即通过学习一个非线性投影函数,把图像空间投影到特征空间中。在这个特征空间里,跨年龄的同一个人的两张人脸的距离会比不同人的相似年龄的两张人脸的距离要小。
针对第二点,考虑到跨年龄人脸的稀缺性。百度用一个用大规模人脸数据训练好的模型作为底座,然后用跨年龄数据对他做更新。这样不容易过拟合。
将这两点结合起来做端到端的训练,可以大幅度提升跨年龄识别的识别率。
另外,百度人脸测试集有2百万人的2亿张图片作为训练样本数据。
专家点评
百度首席科学家吴恩达:小度不仅代表百度人工智能,更代表中国

百度首席科学家吴恩达
世界顶级的科学家也只能理解人脑运作机制的一部分,百度人工智能算法参考人脑较少,更多基于数据分析和深度学习。
在这次比赛中,我们选择的竞赛项目对于机器来说非常非常困难,涉及到人脸识别、语音识别等,但事实上这些对于人类来说却相对容易。人们可以通过直觉来进行很好地判断,比如见到一个人,你不假思索就能认出他是谁。但是机器必须从大量数据进行训练,有些项目中甚至需要识别不清晰的、老旧的照片,所以我认为这对于机器来说是个巨大的挑战。
人脸识别这项技能,人类大脑从上百万年前开始就拥有了,而机器没有直觉,也并没有久远的进化历史,只能靠分析数据来学习。所以这项技能对于哪怕是世界上最先进的AI技术也是非常困难的。
今天,我们基于强大的数据分析,很容易识别两张近期的照片。但是对于识别整容、化浓妆或者十几年跨度的照片,我们并没有大量的数据可以分析。所以这是人脸识别技术遇到的世界性的挑战,也是今天比赛中最大的难点之一。
全世界棋类比赛中顶级的选手很少,人脸识别能力每个人都具备。这次人机大战,是顶级的人脸识别选手和擅长棋类游戏的人工智能比拼,很公平。
人类正在步入人工智能时代,不久的未来,人工智能技术就能应用到走失儿童项目,强大的人工智能创造者依然是人类。
小度目前不能完全明白人类的思想,但是要向王峰还有名人堂的顶级大脑学习, 更好服务人类。小度不仅代表百度人工智能,更代表中国。这次人机大战是百度大脑第一次出现在公开场合的比赛,结果无法知道,只能静待其观。
《最强大脑》Dr.魏:人工智能的后面也是人,是科学家工作的结晶

人认为最简单的事情,对人工智能来说是很困难的。比如运动,虽然三岁的时候你就会爬楼梯,但是现在我们都不知道怎么让机器人像人一样流畅地爬楼梯,特别是楼梯的好多参数是无法预知的时候。
人可以爬各种各样的楼梯,在不同光照条件,不同身体状况等。但是机器人到现在无法象人一样流畅。从进化上来说,运动,包括像爬楼梯这样的运动,大脑很早就学会了。
而人学会围棋对进化中的大脑来说,是很晚才开始玩的。所以,对人来说,楼梯容易一点,围棋难一点。但是可能对机器来说围棋更容易一些,上楼梯更难一些。
感知和运动,这是人类擅长的。这个事情我们就干了几百万年,我们恰恰不擅长逻辑和运算为代表的抽象思维能力。机器不擅长感知和运动。你会发现机器人能下围棋或者记下海量的信息,但是没有办法像人这样运动,或者像人一样去感知这个复杂而快速变化的世界。
人工智能目前擅长的是一个规则定义清楚的东西,他能够解决,就是围棋。围棋是有规则的,他是有一个目标状态,就是我占得去比你大,我把你围死了,国际象棋更是,我就把你kill。目前人工智能算法能解决的问题很多都是有规则的,或者目标状态定义清楚的。但是人类社会,人脑要实现的东西并没有规则,甚至连准确的目标状态都没法提前知道。
人的很多技能,就是一直练下去一直会提升。除了有些是生理上的衰老,你的肌肉系统衰老,那没办法。但是很多技能,如果不被物理身体限制的话,很多技能都是越练越好。另外,人类的整体智商是逐年提升的,所谓的弗林效应,平均智商每10年提高3个点左右,当然,主要提高的是抽象思维能力。
人工智能后面也是人,它是很多工程师和科学家工作的结晶。机器赢人类,这是科技发展的必然结果。这天迟早会到来,只是来的早和晚的事情。
科技的发展,其实是超越我们的想象的。这一天迟早会到来,包括我们目前还不能实现的通用人工智能。只是现在的工程师做的是一个一个区域地攻克,有些硬骨头要啃。在这舞台上你可以说在某些领域人工智能已经达到登峰造极的程度了。
人工智能在面孔识别上超过人类。应该是2012年,就说人脸识别超过了人类的平均水平,是里程碑事件。那现在,百度大脑超越的人类中出类拔萃的一群人。可以说在这个专业方向上,人工智能的准确率已经达到很高的水准,下一步应该是提高运算的效率和能耗。
任何新技术出现的时候老百姓都恐慌,汽车出现恐慌,火车出现恐慌,计算机出现恐慌。这个是终极恐慌,因为汽车出现的恐慌只是这个东西很快,能撞死我。火车也是一样。
老百姓第一想到的是自己的失业,自动化的工厂起来想的是产业工人的失业,人工智能的出现,可能让很多一般智力活动(包括很多白领的工作)甚至专业人员(包括某些领域的医生)的工作受到威胁。但是,我觉得人类的整体的失业率不一定会下滑,有些的工作死了,新的工作又产生了。
百度深度学习研究院主任林元庆: 打败人类不是目的
百度这几年在人工智能上投入了相当的力量做技术研发,我们想在人比较擅长的领域和人较量一下,到底我们的水平做到什么样了,在这些方面是不是和人接近,还是说有很大的差距。
打败人类不是目的,希望我们能演化出很好的技术服务人类。
百度这几年在人工智能上投入了相当的力量做技术研发,我们想在人比较擅长的领域和人较量一下,到底我们的水平做到什么样了,在这些方面是不是和人接近,还是说有很大的差距。