Smart Rookie团队:“菜鸟”搭桥 实现精准匹配
“志同道合、团结友爱,永远怀着一颗‘菜鸟’的心”,三个男生思索良久之后这样评价他们自己。他们,是获得“CCF大数据与计算智能大赛”企业单项一等奖的团队。他们可以在数据挖掘与匹配方面做到快速而准确,也可以在1000多人的决赛现场镇定自若、逻辑清晰,却在回忆制作团队风采展示PPT时表示“这种文艺活儿比算法难太多”。

smart rookie团队获奖
焦虑煎熬的备战期
2016年9月24日,中国•北京梅地亚中心酒店,第三届“CCF大数据与计算智能大赛”开幕,共480支队伍参赛。
赵纪伟、秦剑、苏军平组成的Smart Rookie队便是这其中之一。
见到赵纪伟、秦剑、苏军平的时候,距离他们拿奖已过去了两个多月。作为西安电子科技大学通信工程学院移动计算与通信团队(MCC)的研究生,他们在正月初八就已返校,虽然研二并没有课程,但他们仍需要在实验室跟着导师做项目或是看一些专业相关的资料,“现在也要开始考虑找工作了,所以除了学习,也会留意一些实习的信息”,拿奖对他们来说似乎不过是“简历上能更好看一些”。

赵纪伟决赛答辩
显然,三个工科男生还不善于“应付”这样的谈话,在问及他们参加比赛的感受时,戴着黑框眼镜的秦剑只是低头转着手中的笔,苏军平则侧身看着旁边的赵纪伟和桌子对面的秦剑,最终,还是“老船长”赵纪伟开始回忆他们参赛的日子。“煎熬,很煎熬”,十指交握的赵纪伟不断将双手松开再握紧,似乎已不能再想出更贴切的词语来概括他们备战比赛的三个多月。
“那段儿时间我们都快神经衰弱了,每天早上一睁眼就在想,是不是哪儿出bug了,是不是有什么可以提升成绩的方法,基本上那三个月一直都是这么过来的”。从10月1日初赛正式开始,到12月25日决赛落下帷幕,他们一面要完成老师布置的任务,另一面又得兼顾着比赛。赵纪伟说:“秦剑是比较拼的,有一回他晚上正睡着,突然坐起来就要去实验室改数据,还特执着,说他梦见一个可以提升成绩的方法,把我们弄得哭笑不得。”秦剑看了赵纪伟一眼,低头略带局促地说道:“说这干啥,好羞涩。”
巧妙处理的“领先计”
中国联通“依据用户轨迹的商户精准营销”,这便是赵纪伟他们最终选定的参赛项目。通讯专业出身的他们对网络、数据挖掘等更为熟悉,赵纪伟认为,他们的优势正在于此。
“依据用户轨迹的商户精准营销”其实就是在用户定位和商户坐标的基础上,根据用户画像进行商户和用户的匹配。在此过程中,会涉及到三部分数据,一是用户在某段时间内的位置信息,二是商户的分类和位置信息,三是用户的标签属性信息。Smart Rookie队需要做的便是联系周围商户环境,挖掘用户的行为倾向,进行个性化推荐,本质上就是大数据挖掘、推荐问题。
店铺排序、数据筛减,扎实的基本功为他们省去很多“麻烦”,让他们从初赛开始就一路领先。
联通提供的商户位置均呈无序状,这就意味着在搜索某一店铺时要将所有店铺遍历一遍,“我们发现了这个问题,就把这些店铺按照经纬度坐标进行排序,当用户到达列表内店铺所在经纬度坐标范围内时,就可通过二分查找,迅速定位到店铺的具体位置,这样,我们的复杂度就直接从N方变成了log(n)。”赵纪伟对这个“巧妙的处理”十分满意。
复赛中,联通的训练集数据共有40523条,非空数据(实际推荐店铺)数目为21734,测试集选用训练集中的6111条数据,这比初赛时的数据翻了一倍不止。根据训练集中非空数据的数目,他们发现了一条“黄金特征”,即是在训练集的40523条数据中有18789条记录是没有推荐商户的,而其共同特征是用户在某个地点的停留时间均小于16分钟。据此,他们对测试集6111条记录中对应的用户轨迹停留时间小于16分钟的不推荐任何商户,这直接将他们的线上成绩提高了7个百分点,让他们在复赛中以7‰的优势独占榜首。“7‰在平时可能是很小的数,但在比赛中,这已经是很大的差距了。”苏军平解释道。
双模融合的“杀手锏”
如果说店铺排序、数据筛减都还只是有些“小聪明”的“伎俩”,那么双模型融合的创新做法可称得上是团队的制胜法宝。
模型一(M1)是基于统计的规则模型,根据用户基本标签、用户轨迹之间的距离、用户与店铺之间的距离以及相似用户轨迹的类别比例等特征规则来建模。举例来说,假设小美是一位经常去商场买衣服的用户,联通系统中就会根据她的定位记录打上类似“时尚达人”的标签,当她的定位周边有服装店时,即会给她进行推荐。在这个模型中,用户的定位十分关键。用户实际位置为A点,而定位显示为B点,如何进行用户精确定位是一个难点,他们的选择是泛化误差。“我们的做法就是通过很多用户的定位信息来泛化这个误差,比如很多用户的定位都是在A点这个位置,然后我们看看这些用户中的绝大多数会去的店铺有哪些,用这些光顾度高的店铺位置,反过来确定一个用户的实际定位。”秦剑逻辑缜密地介绍道。
模型二(M2)是xgBoost模型,从给定的复赛数据中做特征工程,从100维特征中根据特征增益的高低,进一步提取出近40维特征,然后采用logstic做一个二分类的处理。赵纪伟用“三个臭皮匠顶个诸葛亮”来风趣地形容这个模型。他说:“xgBoost的基础其实是决策树算法,这是一种概率性的算法,整体思想就是把很多的弱分类器组成一个强分类器。”他进一步解释道:“比如1号树的判断标准是‘天气’,它就可能依据天气晴好判定您去运动或者办公;2号树的标准是‘爱好’,判定您去看电影或者烘焙;3号树的标准是‘行为习惯’,可能判定办公或者购物,每棵树的判定都有不确定性,但是把这三棵树放在一起取交集,就可以判定您今天是办公。以此来推,我们通过某人一系列的行为特征学习到很多树,即使每一棵树的判定都具有不确定性,但是如果树足够多,我们就可以泛化误差,把很多树集成起来,取所有特征判定的交集来做判断,就大大提高了准确率。”
M1的优点在于适应性更强,M2则能对那些训练数据较多的店铺更好地进行拟合,从而对高热度的店铺有更高的推荐准确率。“所以最终我们决定采用模型融合”。首先利用M1进行整体预测,然后利用M2对测试数据预测,取预测用户到达店铺概率在0.5以上的那些训练记录,将其作为PartA;接下来,将PartA预测的那部分数据,从M1的整体预测集中作差集,得到PartB;最后将PartB与PartA两部分预测子集合并,得到最终的预测结果集。
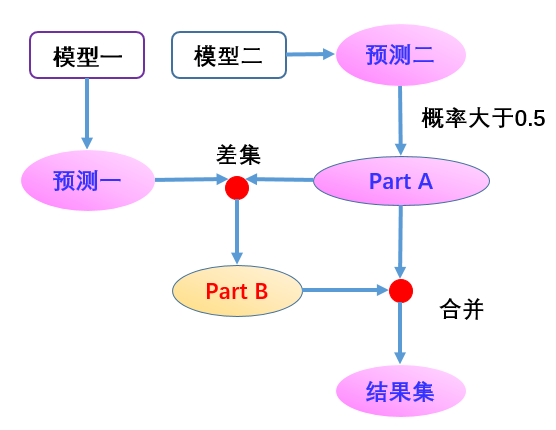
模型融合架构
赛后,Smart Rookie团队的参赛作品便已交由联通研究院做后续开发,也许在某一天,你我的手机上就会收到贴心的店铺推荐了。
延伸 · 阅读
- 2015-11-04Gmail邮件服务推“Smart Reply”可智能回复
- 2017-03-28华为智能手机的竞争战略入选欧洲案例中心和哈佛案例库
- 2017-04-01腾讯启动Super Smart Life Project(SSL工程)