百度大脑发布《2017年语音交互体验蓝皮书》
近日,百度语音发布了2017年语音交互体验蓝皮书的手机篇。该蓝皮书包含了调研和产品试验数据,并据此对语音的交互设计、功能设计、技术设计给出了建议。

只要你的产品设计里应用着语音识别,或计划进军语音交互领域,无论你是否百度语音的用户,这份蓝皮书里都有你关注的内容。
摘要
第一章 语音交互的时代
互联网女皇玛丽·米尔克在2016年的互联网趋势报告中,把语音交互列为2016年的发展趋势之一。事实上我们正在见证着语音交互时代的到来。
1.语音识别准确率不断提升。
语音识别准确率在安静环境下字准率达到97%。
2.语音输入正被应用到越来越多的领域,越来越多的用户从不同的场景接触到语音输入或语音搜索。

3.语音交互日渐成为智能家居和车载等场景的标配。

可以看到,随着识别技术的提升,语音交互正在以其自然、效率等特性,颠覆着传统触摸(按键)的交互方式,而这一转型所释放出来的能量还在不断增长迸发中。
随着语音识别率的提升,越来越多的产品应用着语音交互,语音交互的时代正在到来。这个时代的到来伴随着语音交互体验设计的挑战。而后者优化后所能达到的高度,也一定程度决定了这个时代到来的速度。
目前业界对手机端语音交互体验的研究还处在探索当中,没有系统梳理出交互体验的规范。这份“语音蓝皮书”意在探索手机语音交互设计的规范,和更多的语音从业者(无论是产品设计者还是技术人员,抑或单纯对语音感兴趣的人士)交流我们在语音交互上的思考,为语音体验的提升尽一己之力。
第二章 语音交互设计面临的挑战
1.语音天然属性
根据语音天然的属性,做到扬长避短。
优点:
快。一分钟400字的速度是打字无法匹敌的,因此对一些行业而言,语音的应用能大大地提高效率。
解放双手。至少不用每个字都去敲键盘或按触摸屏了。
更为自然的交互。举个例子,当父母给你发短信时,常常因为不熟悉手机键盘输入而发来错别字,这种情况下,语音显然是更自然的选择。
零学习成本。一些孩子还没能学会打字就会用语音去搜索获取想要的动画片了。对于不会拼音的用户,他不必去学拼音,只要说就可以了。
在启动设计一个好的语音交互时,要清楚地知道语音天然的属性给我们带来的挑战,也要避免在交互设计上的一些观念误区。
第三章 可供参考的几种语音交互设计方法
当我们设计语音交互的时候,有一个目标是一直存在的,即语音输入至少是要和打字输入一样方便的输入。这一目标目前尚未实现,我们需要合理的方法和路径去发现问题,并解决它。
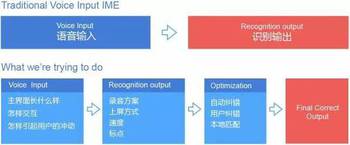
1.流程化分析:语音识别架构的拆解
拆解语音识别流程架构,从输入到输出挖掘更多中间过程,并通过交互、技术(性能)、功能的补充完善整个流程。
2.情感化设计:本能、行为、反思
要激发起用户使用语音输入的冲动,需要用情感化设计去打动用户。
3.无意识原则:To Discover Rather Than Invent
其核心是说去发现本来就在那里但隐而未显的东西,而不是去发明生造。
4.数据驱动设计(Data-driven Design)
数据驱动的设计是面向用户所遇到的困难的设计。事实上这也是我们在探索时所选的最近的一条道路,我们从线上数据中挖掘出当前识别的问题,并给出一套解决方案,落地到产品中去。
5.完整性原则
用户不必频繁在打字输入和语音输入之间做切换。

第四章 语音交互设计的核心原则与辅助原则
1.核心原则
IFF Principle(Intuitive& Fast & Fun)
直觉(intuitive)
快速(fast)
趣味(fun)
2.辅助原则
沉浸(immersion)
一贯(consistency)
控制(control)
在介绍完原则后,我们将从交互层、技术性能、功能层、特殊机制这四个方面来逐一说明。
第五章 交互层
1.主交互方式
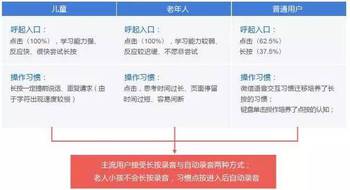
2.主视觉—Voice-Symbolized,AISense,Fun, Transplantable

第六章 技术性能层
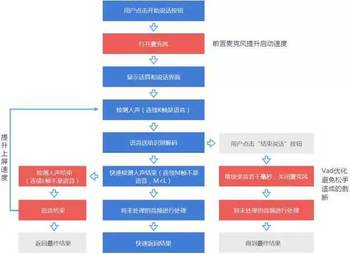
1.快开门缓关门
这一部分是针对速度的系统描述,追求的效果:快开门缓关门。
用户开始说话时,语音启动要快;用户要点击说完按钮时,注意不要截断了用户所说的话。
2.麦克风前置(可能和其他的冲突及解决方案)
?
麦克风前置会带来速度提升的体验,是“快开门”的关键。用户点击按钮后应该支持直接说话,而不需要等到麦克风启动完毕,哪怕等待时间只有300ms,也会影响到用户的体验。甚至,一些用户会提前说话,而没有加载好的麦克风会造成语音截断、识别出错。
3.录音增补VAD判断
用户点击结束(或松手结束)录音后,提供录音补录与VAD判断。用户主动点击说完了,或长按下松手结束,容易点快了或者未说完就不小心松手了,这种情况下识别会不完整。提供录音补录与VAD尾点判断,在遇到用户松手或点按结束却没有说完时,识别还可以继续执行。
整体方案一览:
第七章 功能层——像打字一样好用的语音输入
因为语音识别和打字输入有着天然的差异,我们必须扬长避短。那些打字能够轻松做到而语音还没有做到的,就是此处关键的点。
1.语音纠错功能
语音纠错功能使得从输入、输出到修正的过程形成闭环,用户可以选择不跳出语音输入切回键盘来完成修改。这对需要跳出语音切换回键盘的修改而言,是一个更方便的方案,用户也因此多了一个选择。我们建议两种纠错:指令纠错和自动纠错。
(1)指令纠错
指令纠错通过语音指令实现纠错,同时提供出多个候选。指令纠错的好处是选中过程解放了双手,用户无需手点或滑动选中一片区域
触发方式大概有三类:1、按钮进入纠错模式(与输入识别做区分)。2、识别结果上点击文字出候选。3、自动触发(与输入识别不做区分)。
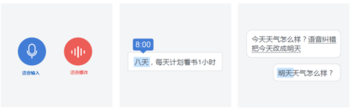
(左图:按钮进入纠错模式;中图:识别结果上点击文字模式;右图:语音触发模式)
我们推荐第三种。
第三种触发方式,能够做到输入与修改的无缝切换,用户不必费力思考究竟处在哪种模式。同时,从纠错的效果上,第一种触发方式没有给出多候选,第二种具有多候选但并不最优。我们推荐的第三种方案,可以再被纠正的地方提供多候选,这样就解决了第二种方式面临的难题,即哪里出候选词的问题。因此,综合纠错触发方式和纠错效果保证的考虑,第三种方式是最优的。
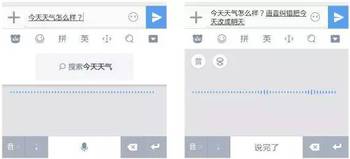
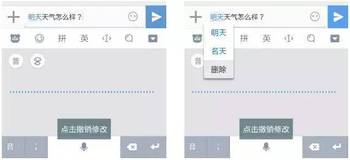
(图:语音指令纠错:把明天改成今天)
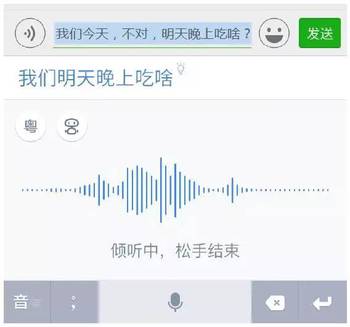
(2)自动纠错
自动纠错则是基于理解的改写。用户在用语音输入时会带有一些误表达,如“今天,不对,明天…”,它需要得到改写,自动纠错将省去用户在识别后的修改操作,在触发自动纠错时会提示用户改写结果,如果合适,用户点击即可完成替换,简单方便。
2.本地资源匹配
打字有通讯录匹配的推荐,语音也应该有。人名往往千差万别,而识别需要依赖普适性。如何正确识别人名是一个问题。

3.场景化识别
用户在搜索、地图、购物app下说出的语料是有一定领域的。这些不同于聊天的场景,如果有相当可预估的语料文本,那么可以进行识别优化。
4.耳语模式
用户出于隐私的考虑,不愿在公共场合下使用语音输入。这是语音天然的缺陷,但是我们应当提供一些措施,去满足这些场合的需求。耳语模式就是提供用户小声说话的识别,用户在此模式下,可以应对一些不能大声说话的场合。
第八章 特殊机制
设立特殊机制的目的是希望带来用户行为的变化、调节用户心理情绪以及辅助识别优化。
1.用户学习机制
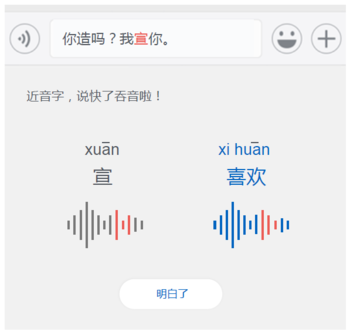
(图:语音识别小提示)
学习机制的形式:
①我们可以通过一些tip去告诉用户哪里错了。
一方面消解用户对未知错误的恐惧,另一方面也实现了用户的一次自我学习。
②游戏方式
龙舟竞赛游戏。用户通过语音控制龙舟。
2.反馈机制
历史反馈机制可以分为个性化反馈与普适性反馈。
个性化反馈:用户有一些自造词或个人的习惯用语,用户通过反馈,实现个性化识别。
普适性反馈:一些地方方言易识别错,通过用户反馈,可以更快地收集带口音识别的数据,实现口音识别自适应技术的优化迭代。
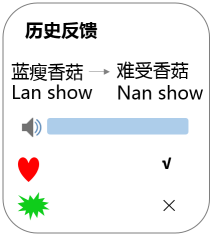
(图:历史反馈卡片的初步构思。包含历史识别结果,对应的音频。用户可以对此评价并反馈正确结果。)
除了以上提纲内容,还有James Landay (斯坦福大学计算机科学教授)、高亮(百度语音技术部总监)等权威人士的专业论点